TFHE-rs v1.4: GPU Performance Breakthrough and More
TFHE-rs v1.4 introduces major improvements in both performance and usability across the CPU, GPU, and HPU backends.
With this releases, Zama continues to enhance its open-source FHE library and make homomorphic encryption more accessible, easy to use, and fast.
Highlights:
GPU performance boost: All GPU operations are now at least 2× faster, with 64-bit division on 4 GPUs or more reaching up to 4× speedups compared to v1.3.
Friendlier parameter APIs: Parameter sets intended for direct use are now grouped into MetaParameters structures, simplifying their integration in the High-Level API.
Improved HPU latency: Integer operation latency has been reduced by up to 45%, thanks to algorithmic optimizations and higher clock frequencies.
CPU: Faster and safer
In TFHE-rs, applying a lookup table generally involves a sequence of several FHE operations: linear transformations, a key switching, and a programmable bootstrapping. This provides an efficient method for reducing the noise inside a ciphertext and evaluating a univariate function homomorphically. The basic data type used to compute such operations is the 64-bit unsigned integer ([.c-inline-code]u64[.c-inline-code]).
In this release, the keyswitching operation has been updated to operate over 32-bit unsigned integers ([.c-inline-code]u32[.c-inline-code]), while the linear and the bootstrapping components still rely on [.c-inline-code]u64[.c-inline-code]. In the codebase, this specific way of computing a lookup table is referred to as [.c-inline-code]KS32[.c-inline-code]. This method has been designed to remain compatible with other parts of the library, making it usable in all scenarios where additional features, such as compression, are required.
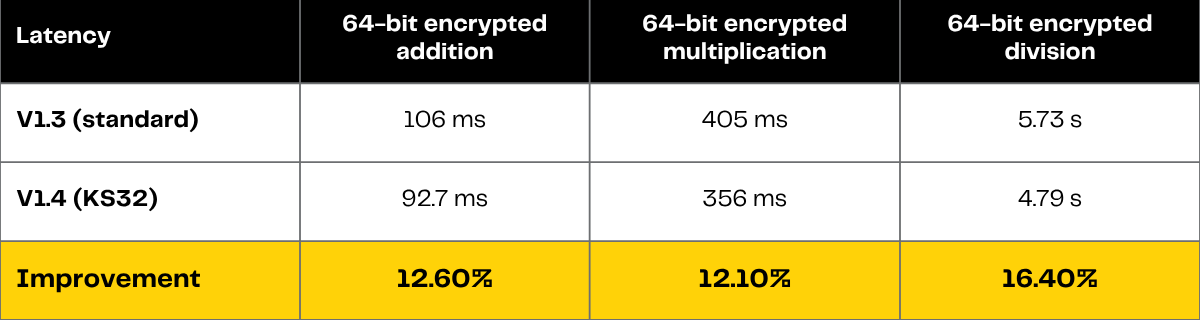
Practically, [.c-inline-code]KS32[.c-inline-code] reduces the keyswitching key size by half and delivers performance improvements ranging from 10 to 19%, depending on the operation, for [.c-inline-code]FheUint64[.c-inline-code] ciphertexts, as detailed in Table 1.
Table 1. Latency of the 64-bit encrypted addition, multiplication and division on CPU. The ciphertexts are encrypted using a TUniform noise distribution, for 128 bits of security and a probability of failure of 2^-128. Results were measured on an AWS hpc7a.96xlarge.
Parameters are now easier to use thanks to the introduction of the so-called MetaParameters, which group together related parameter sets intended to be used jointly.
Here is a quick example on how to use KS PBS meta-parameters enabling all the features of the High-Level API:
use tfhe::prelude::*;
use tfhe::shortint::parameters::v1_4::meta::cpu::V1_4_META_PARAM_CPU_2_2_KS_PBS_PKE_TO_SMALL_ZKV2_TUNIFORM_2M128;
use tfhe::shortint::parameters::v1_4::*;
use tfhe::{generate_keys, set_server_key, ConfigBuilder, FheUint8};
fn main() {
// New MetaParameters approach
{
// The V1_4_META_PARAM_CPU_2_2_KS_PBS_PKE_TO_SMALL_ZKV2_TUNIFORM_2M128 parameters support
// all features for the HL API.
let (client_key, server_key) =
generate_keys(V1_4_META_PARAM_CPU_2_2_KS_PBS_PKE_TO_SMALL_ZKV2_TUNIFORM_2M128);
set_server_key(server_key);
let clear_a = 27u8;
let clear_b = 128u8;
let a = FheUint8::encrypt(clear_a, &client_key);
let b = FheUint8::encrypt(clear_b, &client_key);
let c = a * b;
let decrypted_c: u8 = c.decrypt(&client_key);
assert_eq!(decrypted_c, clear_a.wrapping_mul(clear_b));
}
// Old manual approach where parameters had to be matched manually
{
let config = ConfigBuilder::with_custom_parameters(
V1_4_PARAM_MESSAGE_2_CARRY_2_KS_PBS_TUNIFORM_2M128,
)
.use_dedicated_compact_public_key_parameters((
V1_4_PARAM_PKE_TO_SMALL_MESSAGE_2_CARRY_2_KS_PBS_TUNIFORM_2M128_ZKV2,
V1_4_PARAM_KEYSWITCH_PKE_TO_SMALL_MESSAGE_2_CARRY_2_KS_PBS_TUNIFORM_2M128_ZKV2,
))
.enable_compression(V1_4_COMP_PARAM_MESSAGE_2_CARRY_2_KS_PBS_TUNIFORM_2M128)
.enable_noise_squashing(V1_4_NOISE_SQUASHING_PARAM_MESSAGE_2_CARRY_2_KS_PBS_TUNIFORM_2M128)
.enable_noise_squashing_compression(
V1_4_NOISE_SQUASHING_COMP_PARAM_MESSAGE_2_CARRY_2_KS_PBS_TUNIFORM_2M128,
)
.enable_ciphertext_re_randomization(
V1_4_PARAM_KEYSWITCH_PKE_TO_BIG_MESSAGE_2_CARRY_2_KS_PBS_TUNIFORM_2M128_ZKV2,
)
.build();
let (client_key, server_key) = generate_keys(config);
set_server_key(server_key);
let clear_a = 27u8;
let clear_b = 128u8;
let a = FheUint8::encrypt(clear_a, &client_key);
let b = FheUint8::encrypt(clear_b, &client_key);
let c = a * b;
let decrypted_c: u8 = c.decrypt(&client_key);
assert_eq!(decrypted_c, clear_a.wrapping_mul(clear_b));
}
}
This release introduces the rerandomization feature - ReRand, which ensures security of FHE computation in the strong IND-CPA^D model (sIND-CPA^D) defined in this paper by Bernard et al.
The v1.4 CPU backend also brings the following features:
KVStore (Key-Value Store): a homomorphic hashmap that stores encrypted values under clear keys and supports inserting, updating, or retrieving these values either with clear keys or through blind process using encrypted keys;
Flip operation: swaps two encrypted inputs based on an encrypted boolean value;
Support for MultiBit PBS: enables noise squashing;
Support for FHE Pseudo Random Generation: allows drawing uniform values between 0 and any positive integer bound, with a tunable bias.
GPU: A major performance leap
TFHE-rs v1.4 brings major GPU performance improvements, in particular:
The bootstrapping operation now takes less than a millisecond for a single input: more details are available in this blogpost.
This results in a 2× speedup for all operations compared to v1.3.
Integer logarithm was reworked and is 3× faster.
Encrypted random generation was reworked and is 10× faster.
The multiplication on multiple GPUs is 3× faster thanks to the improvements in the multi-GPU logic;
64-bit integer division operation is 4× faster on 4 GPUs or more, thanks to the introduction of a new algorithm for multi-GPU with 2 bits of message and 2 bits of carry in ciphertexts.
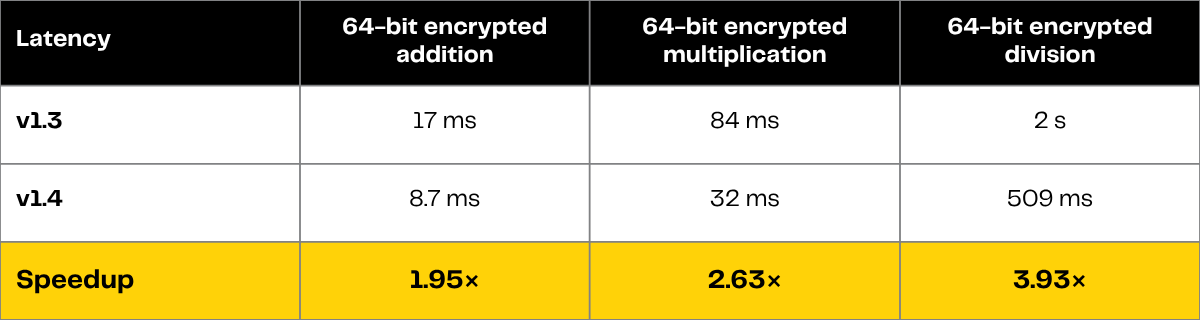
The latencies of the 64-bit encrypted addition, multiplication and division on 8xH100 GPUs in TFHE-rs v1.4 (as compared to v1.3) are reported in Table 2 below.
Table 2. Latency of the 64-bit encrypted addition, multiplication and division on GPU. The ciphertexts are encrypted using a TUniform noise distribution, for 128 bits of security and a probability of failure of 2^-128. Results were measured on the Nebius platform with 8xH100 GPUs.
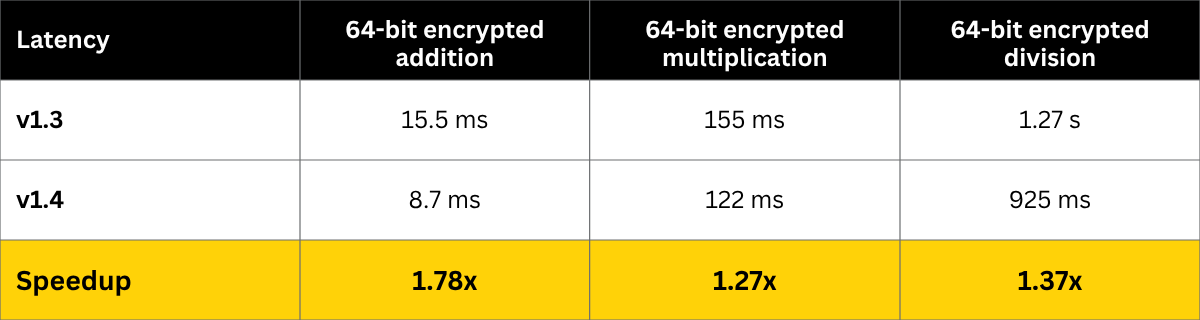
The operations throughput has also improved compared to the previous version, as shown in Table 3 below.
Table 3. Throughput of the 64-bit encrypted addition, multiplication and division on GPU. The ciphertexts are encrypted using a TUniform noise distribution, for 128 bits of security and a probability of failure of 2^-128. Results were measured on the Nebius platform with 8xH100 GPUs.
All latency and throughput measurements are available in the documentation. TFHE-rs v1.4 also introduces several new features on GPU:
Noise squashing can now be performed with multi-bit parameters, resulting in a 4x speedup compared to the classical noise squash on GPU.
128-bit compression can now be performed on GPU.
Thedrift technique for noise reduction in the classical bootstrap has been replaced by the mean reduction technique, eliminating the need for a dedicated key.
HPU: enhanced backend, faster HPU
On the FPGA side, TFHE-rs v1.4 introduces a few performance enhancements:
Move from 350Mhz to 400Mhz has been enabled by modifying the reset signal distribution and finding more adapted compilation strategy with Vivado 2025.1
Improved NOC (Network On Chip) bandwidth for key loading: both bootstrapping and key-switching key loading were delayed by constant HBM row swapping and too small command buffers in the NOC.
Accumulator structure has been adapted to better fit the current size of the PBS batch (12).
Table 4. Latency of the 64-bit encrypted addition, multiplication and division on x1 HPU. The ciphertexts are encrypted using a TUniform noise distribution, for 128 bits of security and a probability of failure of 2^-128.
On the hpu-backend side, the effort have been focused on stability and quality, and some operation performance have been enhanced:
2 new SIMD operations added: ADD_SIMD & ERC20_SIMD have been designed to execute 12 operations in a single HPU instruction. ERC20_SIMD is executing x12 ERC20 transfers which are each a transfer of an amount A from a source S to a destination D: (S, D, A) -> if S > A then (S-A, D+A) else (S, D). We have been able to reach 87 ERC20 per second on a single HPU using this new instruction.
MUL operation scheduling has been slightly improved.
HPU IOp & IOp acknowledge queue stability have been improved in new versions of AMC Firmware and AMI Driver (now using v3.1.0-zama).
Integer throughput benchmarks can now be executed on HPU and the High-Level API bench includes measurements on ERC20_SIMD IOp throughput.
With v1.4, TFHE-rs makes FHE faster to run and easier to use, empowering builders to bring privacy to real-world applications.

.svg)
.png)

